Attention based learning is when you have a sequence input where only part of it is relevant and you want your neural network to explicitly choose what is relevant. For example, if you are translating a sentence from English to French, only some of the words in the English sentence are relevant to generating the next word in the French sentence. So part of your neural network would be dedicated to weighing the importance of each English word in the context of what the neural network intends to generate next in the French sentence. This attention module would work by taking two inputs:
- an embedded word vector from the English sentence
- the current state of the recurrent neural network that is encoding what has been generated up to now
This technique has not only been used for machine translation but also for image captioning (only attend to parts of the image for every word being generated) and neural turing machines (only attend to parts of the tape with every operation). Just look at what Colah has to say about it. However this is just soft attention, which is easy. It's called soft attention because you still partially attend to every part of the input; it's just some parts get very little attention. This means that it's still possible to measure the effect of a part of an input and so it's still possible to determine, by gradient descent, whether its attention should be increased or decreased.
Hard attention, on the other hand, either completely includes or excludes elements of the input. How would you do this in a neural network? You'd need to use thresholding for example, where if the value of a neuron is above a threshold then it outputs a one, zero otherwise. You can also use argmax which selects the neuron with the greatest value and sets it to one and all the others to zero. Unfortunately both of these solutions are undifferentiable and that makes direct gradient descent ineffective if they are used in a hidden layer (in an output layer you can just maximize their continuous values and then threshold them at test time). It would be the same situation neural networks had in the past when they couldn't have a hidden layer because there was no known optimization algorithm for 2 layers of thresholding neurons.
It would be nice to somehow make neurons that have discrete outputs but which can still be trained by gradient descent. One way to do this is to use stochastic neurons which output discrete values based on a probability that can be tweaked. The simplest probabilistic neuron is the Bernoulli neuron which outputs a 1 with probability "p" and a 0 otherwise. Let's assume a simple attention based neural network that uses one Bernoulli neuron as an attention module and one normal sigmoid neuron as a feature extraction neuron. The Bernoulli neuron's output is multiplied by the normal neuron's output in order to gate it. Both neurons take the same single number as input.
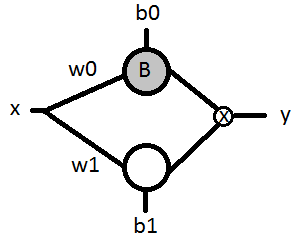
The grey neuron with a "B" inside is the Bernoulli neuron, "w0" and "w1" are weights and "b0" and "b1" are biases. If we had to turn this into an equation in order to differentiate it, we'd end up with this:
$$y = B_x \cdot sig(w_1 x + b_1)$$
where "B_x" is a random variable that is dependent on "x". Unfortunately random variables "hide" their inner workings and we cannot express their probability as part of the equation. This means that we cannot optimize "w0" and "b0" by gradient descent as it would be meaningless to differentiation with respect to "w0" given that it's not in the equation. In fact "B" is treated as a constant in the above equation and we can still differentiate the equation with respect to all the other parameters. Note that this situation is different from dropout, where you randomly multiply some of the neuron values by 0 in order to avoid overfitting. In the case of dropout, the above equation would be enough as we're not optimizing the value of the dropout random variable.
There is a simple solution to this problem however. Instead of finding the gradient of "y", we can find the gradient of the expected value of "y". The expected value is the mean value you get when running a stochastic function over and over again. For example, if you're tossing a fair coin, with one face representing a 1 and the other face representing a 0, the expected value is 0.5. However, if you're tossing an unfair coin where the "1" face comes up 75% of the time, then on average you will get a value of 0.75. In general, the expected value of a discrete probability distribution, such as the Bernoulli distribution, can be found using the following equation:
$$E[X] = \sum_{v \in X} p(v) \cdot v$$
that is, just multiple each value by its respective probability and take the sum. In the case of a coin with probability of the "1" face coming up being "p" (a Bernoulli distribution), the expected value is $1 \cdot p + 0 \cdot (1-p)$ which equals "p". We can take advantage of the expect value by using gradient descent to minimize the expected error rather than the error itself. This would expose the parameters that determine the probability of the Bernoulli neuron and we would be able to use gradient descent as usual.
Let's take a concrete example of an error function. We want to minimize the sum square error of the neural net such that when given a 0 it should output a 1 and when given a 1 it should output a 0 (a logical NOT). This is what the error function (called the cost function) would look like, together with the error function of a single input:
$$
\begin{align}
C &= \sum_{(x,t_x) \in \{ (0,1),(1,0) \}} (t_x - B_x \cdot sig(w_1 x + b_1))^2 \\
C_x &= (t_x - B_x \cdot sig(w_1 x + b_1))^2 \\
\end{align}
$$
Let's focus on just the single input error function. The expected error would look like:
$$
\begin{align}
E[C_x] &= sig(w_0 x + b_0) \cdot (t_x - 1 \cdot sig(w_1 x + b_1))^2 + (1 - sig(w_0 x + b_0)) \cdot (t_x - 0 \cdot sig(w_1 x + b_1))^2 \\
&= sig(w_0 x + b_0) \cdot (t_x - sig(w_1 x + b_1))^2 + (1 - sig(w_0 x + b_0)) \cdot (t_x)^2 \\
\end{align}
$$
Remember that expected value finds the sum of all the possible values of the stochastic function due to randomness multiplied by their respective probability. In the case of our neural net, the two possible values due to randomness are caused by the Bernoulli neuron "B" being either 1 with probability $sig(w_0 x + b_0)$ or 0 with probability $1 - sig(w_0 x + b_0)$. Now we can find the gradient of the expected error and minimize it, which would include optimizing the parameters determining the probability of the Bernoulli neuron.
In general it might not be tractable to expose all the possible values of a stochastic neural network, especially when multinoulli neurons are used where there are many possible discrete values instead of just 0 or 1 and especially when there are multiple such neurons whose values must be considered together, creating a combinatorial explosion. To solve this problem, we can approximate the expected error by taking samples. For example, if you want to approximate the expected value of a coin, you can toss it a hundred times, count the number of times the coin gives the "1" face and divide by 100. This can be done with a stochastic neural network, where you run the network a hundred times and calculate the mean of the error for each training pair. The problem is that we don't want the expected error, but the derivative of the expected error, which cannot be calculated on the constant you get after approximating the expected error. We need to take samples of the expected derivative of the error instead. This is what the expected derivative of the error looks like:
$$
\begin{align}
\frac{dE[C_x]}{dw} &= \frac{d}{dw} \sum_{v \in C_x} p(v) \cdot v \\
&= \sum_{v \in C_x} \frac{d}{dw} (p(v) \cdot v) \\
\end{align}
$$
The problem with this equation is that it can't be sampled like an expected value can so you'll end up having to calculate the full summation, which we're trying to avoid. The solution to this is that we continue breaking down the algebra until eventually we get something that can be approximated by sampling. This has been derived multiple times in the literature and so it has multiple names such as REINFORCE, score function estimator, and likelihood ratio estimator. It takes advantage of the following theorem of logarithms: $\frac{d}{dx} f(x) = f(x) \cdot \frac{d}{dx} \log(f(x))$
$$
\begin{align}
\frac{dE[C_x]}{dw} &= \sum_{v \in C_x} \frac{d}{dw} (p(v) \cdot v) \\
&= \sum_{v \in C_x} \left( p(v) \cdot \frac{d}{dw} v + v \cdot \frac{d}{dw} p(v) \right) \\
&= \sum_{v \in C_x} \left( p(v) \cdot \frac{d}{dw} v + v \cdot p(v) \cdot \frac{d}{dw} \log(p(v)) \right) \\
&= \sum_{v \in C_x} p(v) \cdot \left( \frac{d}{dw} v + v \cdot \frac{d}{dw} \log(p(v)) \right) \\
&\approx \frac{\sum_{i = 1}^{N} \frac{d}{dw} \tilde{v} + \tilde{v} \cdot \frac{d}{dw} \log(p(\tilde{v}))}{N} \text{ where } \tilde{v} \sim{} C_x \\
\end{align}
$$
The last line is approximating the derivative of the expected error using "N" samples. This is possible because probability "p" was factored out inside the summation, which gives it the same form of an expect value equation and which hence can be approximated in the same way. You might be asking how it is that you can find the probability of each possible value. As long as you have access to the values returned by the stochastic neurons, you can use a dictionary to map values to their respective probabilities and multiply them together if necessary. The following is the derivative of the above Bernoulli NOT gate:
$$
\begin{align}
C_x &= (t_x - B_x \cdot sig(w_1 x + b_1))^2 \\
\frac{dE[C_x]}{dw_0} &\approx \frac{\sum_{i = 1}^{N} \left( \frac{d}{dw_0} (t_x - B_x \cdot sig(w_1 x + b_1))^2 \right) + (t_x - B_x \cdot sig(w_1 x + b_1))^2 \cdot \left(
\frac{d}{dw_0}
\left\{ \begin{array}{lr}
\log(sig(w_0 x + b_0)) & : B_x = 1 \\
\log(1 - sig(w_0 x + b_0)) & : B_x = 0 \\
\end{array} \right.
\right) }{N} \\
\end{align}
$$